2022年11月10日,openEuler社区联合openEuler SDS SIG和bigdata SIG开展的“openEuler Meetup—分布式存储与大数据”圆满结束。活动吸引了来自ISV、互联网、运营商等30+企业近两百名专家和开发者踊跃参与。 线上会议、交流群讨论热烈,开发者在提问环节对分布式存储及大数据领域关键技术与讲师进行深入的交流互动。

视频回顾
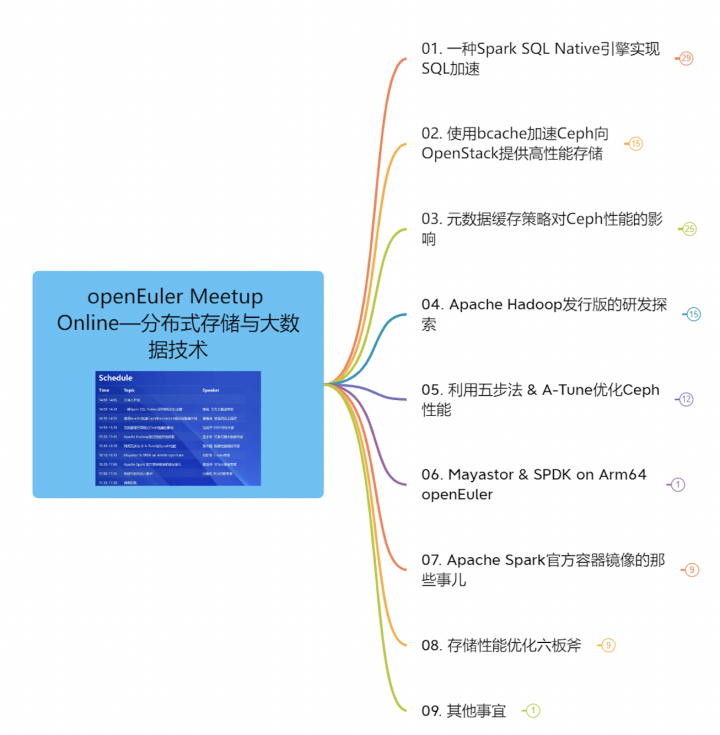
一种Spark SQL Native引擎实现SQL加速
一种Spark SQL Native引擎解决方案,通过执行层可灵活定制算子实现策略,兼容codegen和静态编译方式,基于列式内存布局实现向量化,结合LLVM动态优化生成代码,提升Spark SQL的性能。

点击查看
使用bcache加速Ceph向openstack提供高性能存储
由于openstack本地存储已无法满足数据安全性要求。ceph凭借其高扩展、高可靠、高性能等显著特性,成为openstack持久化存储的首选。然而由于网络带宽,磁盘性能及硬件设施成本等因素,千兆网卡+HDD的ceph组合已经难以满足openstack高并发操作的需求。基于此,可优化传统的ceph存储组合,使用SSD+HDD+万兆网卡的组合形式,使用bcache缓存方案加速OSD,向openstack提供高性能持久化存储方案。

点击查看
元数据缓存策略对Ceph性能的影响
介绍Ceph的总体架构以及元数据缓存策略对性能影响。

Apache Hadoop发行版的研发探索
介绍Redoop Enterprise发行版本研发和演化路径,对比其他发行版本分析背后策略,探索商业发行版本技术策略、驱动力和发展模式。

点击查看
利用五步法 & A-Tune优化ceph性能
结合具体项目案例介绍利用五步法优化分布式存储软件ceph,以及感知上层业务场景、自动完成调优配置的智能调优工具A-Tune。

Mayastor & SPDK on Arm64 openEuler
SPDK作为一个高性能的用户态存储基础开发库套件天然集成NVMe-oF RDMA 和 NVMe-oF TCP,极大地方便存储数据面的开发工作。当前多数云原生存储开源项目和传统的存储项目都是基于SPDK支持了NVMe-oF功能。本次分享将讲解SPDK和Mayastor在ARM64 openEuler上的软件生态使能情况,二者在ARM64 openEuler上的性能测试结果,以及在过程中遇到的问题和性能测试经验等。

Apache Spark 官方容器镜像的那些事儿
Apache Spark是一款分布式内存计算的统一分析引擎;而随着云原生架构的逐渐成熟,Spark容器化部署也越来越成熟,一个满足用户需求、高质量的应用容器镜像变得尤为重要。本次分享介绍了Apache Spark 官方容器镜像支持的那些事儿,包括:Apache Spark社区容器化项目规划和技术路线,在不同架构和操作系统的支持和实践。

点击查看
存储性能优化六板斧
结合项目实践经验,分享通过六种优化手段(诸如调度、部署、瓶颈点、微架构优化,网卡中断绑核,基础性能库),提升分布式存储性能。

学霸风采
本次openEuler Meetup Online设置了“随堂笔记奖项“,不少开发者同学在活动结束后把内容详尽,干货满满的笔记交作业给openEuler小助手,快来一览节选学霸们的精华笔记~



本次openEuler Meetup Online分享回放已上传openEuler的B站合集,欢迎大家学习回顾: https://space.bilibili.com/527064077/channel/seriesdetail?sid=2775239
欢迎添加欧拉小助手微信“openeuler123”加入技术交流群