本系列文章翻译、修改自 A Crash Course in Linux Networking, 作者 David Guyton
译文相比原文有较大的的改动及精简,若感到困惑请参阅原文
网络流量的路由和过滤
Linux 网络数据包的路由过程和路由策略稍微有些复杂,并不是那么容易理解。从较高的角度来看,Linux 网络路由可以分为两个核心部分:其一是实际的路由策略执行过程,其二是对数据包进行 mangle 的过程。这两部分组合使用,可以发挥远超普通的、基于路由表进行网络路由的系统。Linux 路由要解决的主要问题包括:
- 当内核要向某个特定的网络设备发送数据包的时候,该如何选择发送路径?
- 当内核收到一个外部设备发来的数据包时,该怎么处理这个数据包?
mangling (mangle) 一词可以直译为破碎、拆解,但在 Linux 网络流量管理中,其表达的意义更接近于 “篡改” - 它表示,当前主机作为数据包的传递者(经手)或接收者,对该包信息进行修改,以实现自己的某些目的。修改的范围可以是 header ,也可以是包的内容。最常见的 mangle 就是 NAT 和端口转发,其他还可以实现负载均衡、实现特殊的安全规则等。
Linux 对流量的处理手段有两种:路由(Routing)和过滤(Filtering)。"路由"指从主机发出的数据包该使用的传递路径,所有的网络数据都在路由上传递, 解决 “去哪里” (where)的问题。“过滤” 指的是对进入和离开当前主机的数据包进行操作(接收 / 传递下去 / 丢弃)或修改(修改包头或内容),解决 “发送什么” (what)和 “如何发送” (how)的问题。过滤的最好例子就是防火墙。
在网络中,“路由” 既可以是动词也可以是名词。作为动词时,表示为数据寻找一条可以将之传输到目的地的路径——在 Linux 主机上,就是为一个拥有特定目的地 IP 的数据包寻找该从哪个网卡发出,发到哪个网关上去。作为名词时,指的就是一条已经确定的可行路径——从哪个网卡,经由哪些网关可以到哪里。
路由一词的英文是 “route” ,指的就是可以通往哪里的一条道路。
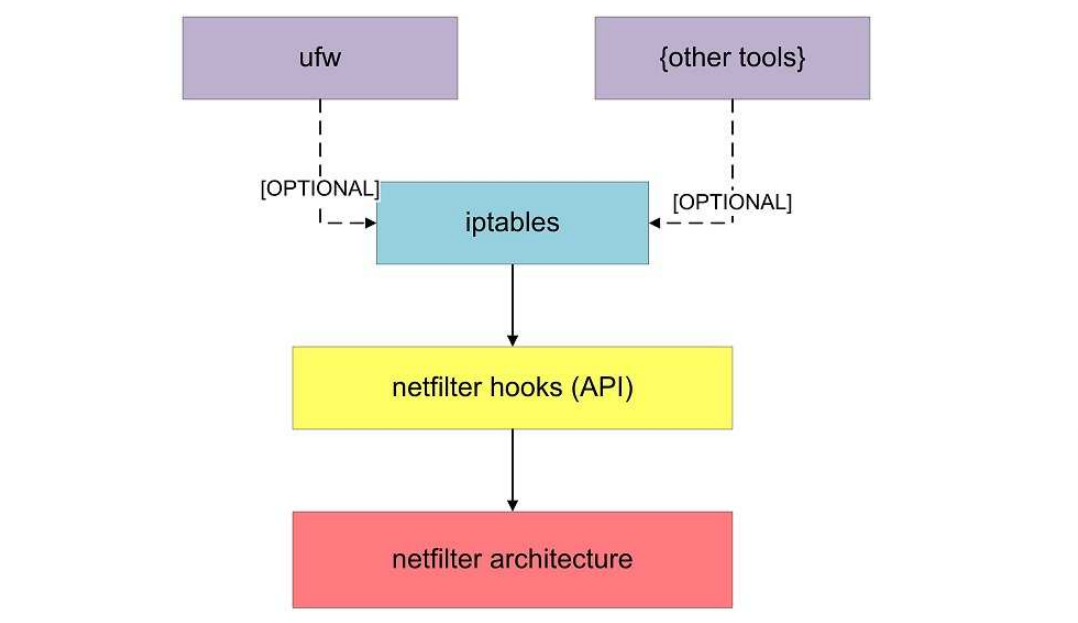
绝大多数 Linux 发行版的流量过滤机制的核心是 netfilter (其是 Linux 的防火墙),通过 iptables 和 ip route 两个应用层工具对其进行配置和管理。 Netfilter 本身包括两个核心组件:配置内核钩子(kernel hooks)的 API 和底层网络代码。
部分 Linux 发行版提供了一种完全独立的、用于操作 netfilter 的工具 ufw (“Uncomplicated FireWall”),他其实是个 iptables 的前端,部分人觉得这个东西比 iptables 简单些。
Linux 网络工具简史
Linux 网络工具复杂而漫长的历史,是折磨初学者的重要因素之一。从 1995 到 2001 年间,Linux 内核网络发生了很大的变化,这期间的相当多代码一直用到了 2014 年 —— 那年也只是对接口进行了修改,核心逻辑一直没变。二十多年过去,现在的 Linux 服务器上还跑着当初的代码。
下面是用户态网络工具的历史:
| 工具 | 发布时间 | 内核版本 | 已废弃 | 特性 |
|---|---|---|---|---|
| ipfwadm | 1995 | 1.2.1 | 是 | Linux 的第一个数据包过滤工具 |
| ipfwadm (v2) | 1996 | 1.3.66 | 是 | 引入 Chain 概念(IN, OUT, FORWARD) |
| iproute | 1997 | 2.0 | 是 | 最初的 ip 工具(引入了 RPDB) |
| ipchains | 1999 年 5 月 | 2.2 | 是 | 可由用户创建 ipchains ,引入 fwmark |
| iproute (v2) | 1999 年 9 月 | 改进 ip 工具 | ||
| iptables | 2000 年 3 月 | 2.3 | 初次发布,替代 ipchains、fwmark | |
| 2001 | 2.4 | iptables 包过滤和包头 mangling | ||
| nftables | 2014 年 1 月 | 3.13 | 用于替换 iptables |
1995 年的 1.2.1 内核首次提供了防火墙管理工具 ipfwadm ,这个名字是 “IP FireWall ADMinstration” 的简写。通过该工具,系统管理员第一次能够对数据包做检查并调整内核的数据包处理行为。该工具在几年后被 ipchains 取代,而 ipchains 仅在一年后就被 iptables 取代了。
nftables 是用来替代 iptables (以及不那么常见的 arptables 和 ebtables )的。nftables 将众多功能集合在了同一个工具中,为 netfilter 的各种内核钩子提供单一的接口,一起合并的也包括各种工具的扩展(比如 CONNTRACK)。
ipchains
“链”(chains)是 Linux 网络中的一个基础概念,1996 年其刚发布的时候只有三条链:IN, OUT 和 FORWARD ,这三个链对应了经过一台主机的数据包的三个主要路由阶段。IN 表示从外部进入到本主机的数据包,OUT 表示从本主机发出到其他设备的数据包,FORWARD 表示经过本主机的数据包(流经,即从一个主机发出,需要路过本主机到另一个主机)。可以把链想象成是主机中的高速公路,能够把流量引导向特定的方向,但无法对数据包进行修改。
路由策略数据库 (RPDB, Routing Policy DataBase) 的演进之路
1997 年的 Linux 2.0 是 Linux 社区历史上的一个重大节点。该版本完全重写了网络的底层代码,引入了全新的网络管理工具 iproute 和路由策略数据库(RPDB, Routing Policy DataBase)。
RPDB 提出了多路由表,有了 “路由表的表”(a table of routing tables) —— Linux 在 2.0 之前的版本中使用传统的单路由表模型。在 2.2 内核引入 ipchains 的不久后,iproute 发布了 v2 版本 iproute2 。相较于 Alexey Kuznetsov 开发的第一版,引入了今天被称为过滤规则的规则层(layer of rules)—— 实际上是把一部分 ipchains 的功能在 RPDB 里面又重复实现了一遍,这引起了关于到底该在哪里修改数据包、在哪里实现 NAT 以及该在哪里操作 netfilter (netfilter 是 Linux 内核中的网络管理工具)的争论。今天我们用的 ip route 和 ip rule 命令就是 iproute2 的一部分,其取代了初版 iproute 中的 route, ifconfig netstat 工具。
半年后,iptables 随着 2.3 内核发布了,其取代了 ipchains ,并实现了一部分 iproute2 提供的功能。在 2.4 及 2.6 内核发布后,iproute2 中的很多功能都废弃了。至此,iptables 就成为了管理数据包 mangling 和实现 NAT 的最主要工具。iptables 留下了 ipchains 中的链的概念,将内置链的数量扩展为五个,并允许用户自行添加自定义的链。
netfilter
netfilter 负责网络数据包管理和 NAT,其由两部分组成:1) 一组内核钩子;2) 将命令转化为内核行为的工具。各种 xx-tables 工具实际都是和 netfilter 交互的接口。
iptables
iptables 是 Linux 网络数据包管理发展历程中的一个里程碑,其对 ipchains 做了进一步的升级,且今天仍被广泛使用。iptables 无法引导流量的方向,但能够修改网络数据包。
链(chains)会调用一系列的表(tables),提供细粒度的数据包过滤功能。这样做的主要好处是过滤规则都集中在一个地方。数据流由链控制,并根据需要调用表。一个表包含一组数据包过滤指令,但无法改变数据包的流向。
需要注意的是,尽管 ipchains 已经被淘汰了,但链本身仍存在于 Linux 中,而且是 iptables 中必不可少的一部分。
NFTables
nftables 是 iptables, ip6tables, arptables 和 ebtables 的替代品。
nftables 和 iptables 不同,nftables 完全绕过了 netfilter 的翻译工具(指把命令翻译成内核可执行的操作流程的工具),直接把数据送往 netfilter 的内核接口(如下图所示)。举例来说,删掉 netfilter 会导致 xx-tables 全部无法工作,但 nftables 还能正常工作
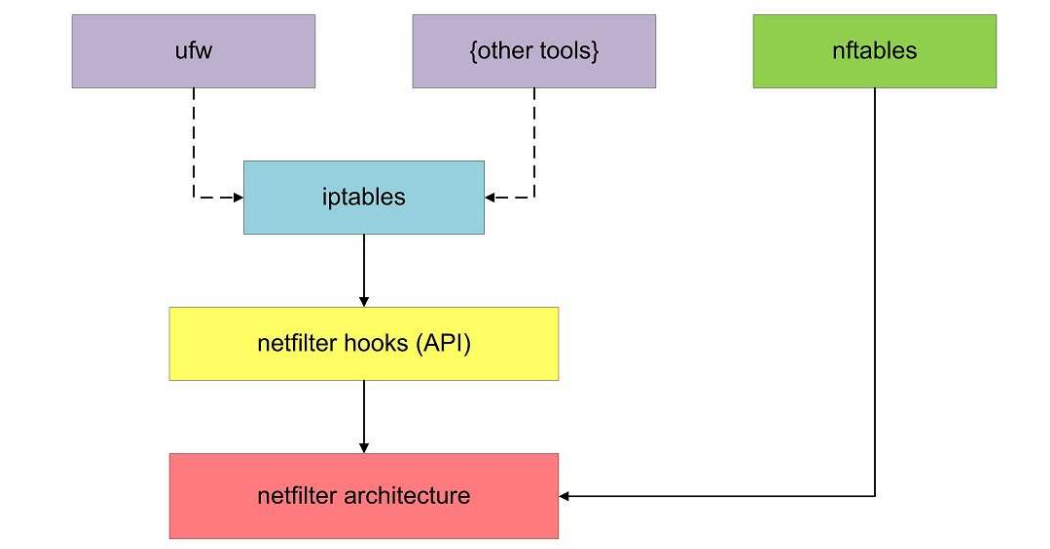
虽然 nftables 希望取代 iptables ,但到目前 iptables 仍是事实上的标准工具。nftables 相较于 iptables 有如下优点:
- 命令结构更加简洁,能用更少的命令实现相同的过滤规则
- 链是完全可配置的,不存在 iptables 中的基本链
- 支持命令串联(concatenation,就是把多个类型的条件组合到同一个命令中)
- 能在不更新内核的情况下支持新协议
- 可以使用单一的表达式来混合表示匹配(matches)和目标(targets)
- 同时支持 IPv4/v6
在 nftables 之前,Linux 的网络管理方式是把所有的控制步骤都放在内核中,而 nftables 则是使用一个虚拟机来实现数据包操作,只有在所有的修改都完成之后才把数据包送给内核。