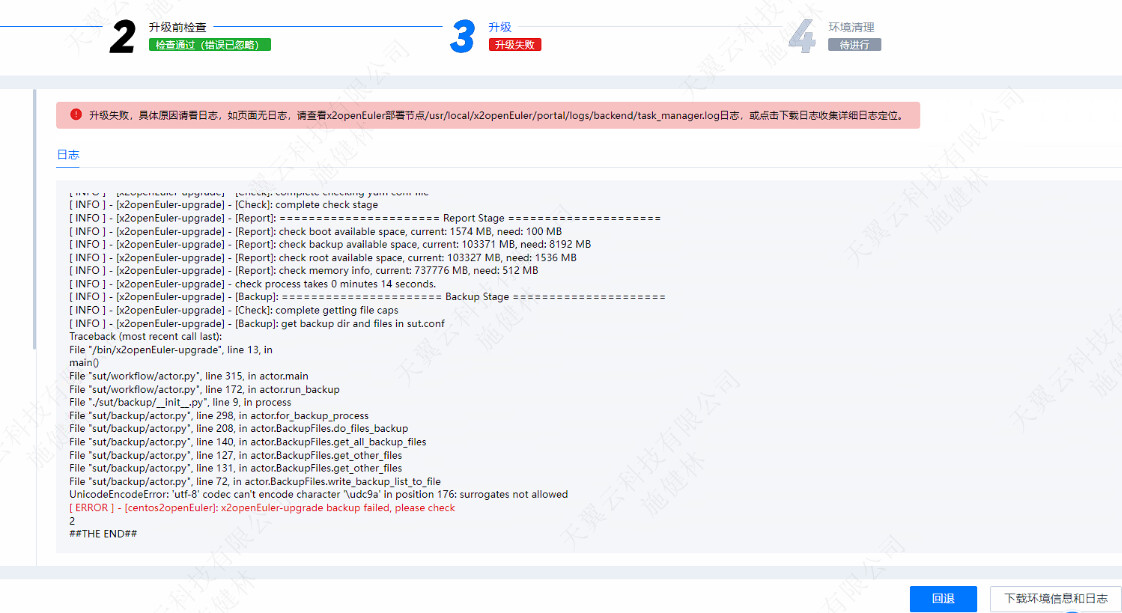
把下面的代码放到一个.py结尾的文件中,使用python执行下,可以找到哪个文件有乱码
import os
def covert_to_utf8(filename):
try:
encode_filename = filename.encode("utf-8")
return encode_filename, None
except UnicodeEncodeError as e:
print("错误的文件名:",filename,str(e))
return None, str(e)
def check_utf8_file(dirname):
flag = 0
for maindir, subdir, file_name_lists in os.walk(dirname):
try:
covert_to_utf8(maindir)
except Exception as e:
print(e)
print("{0}/{1}".format(maindir,subdir))
break
for filename in file_name_lists:
apath = os.path.join(maindir, filename)
try:
utf8_filename, error = covert_to_utf8(apath)
except Exception as e:
flag = 1
print(e)
print("{0}/{1}".format(maindir,subdir))
break
if flag:
break
dirname_list=["/var"]
for dirname in dirname_list:
check_utf8_file(dirname)
其中dirname_list是x2工具上备份的文件夹,比如/var,/usr…