问题背景
我们l7probe探针程序会观测http连接,并对做一些吞吐量、时延等的统计。实际测试中发现该程序在高压力流量下会将CPU打满,因此考虑进行性能优化。
注:被测程序l7probe在这里。
测试环境
环境: HCS 821 B010 (OpenEuler-22.03 LTS SP1)
CPU core 8
Memory(MB) 16
问题复现
测试条件
l7probe采用debug模式编包;服务端程序为app.py(处理能力较弱);JMeter施压如下:
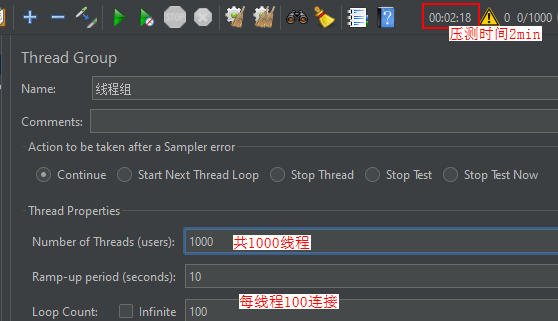
测试结果
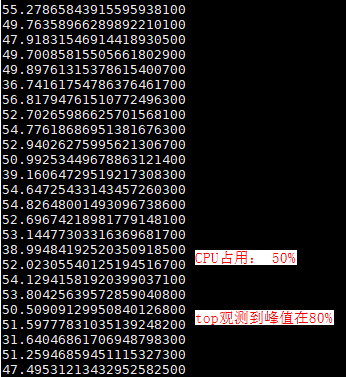
备注:本篇介绍的性能测试过程,均对被测程序和可能影响程序分别做了绑核操作,http服务端app绑核cpu0~2、l7probe绑核cpu7。
火焰图分析
本次性能优化主要使用了A-Ops火焰图特性,具体介绍和安装参考这里。
启动stackprobe,并指定观测l7probe进程:
curl -X PUT http://localhost:9999/flamegraph -d json='{"cmd":{"probe":["oncpu", "mem"]},"snoopers":{"proc_name": [{"comm":"l7probe"}]}, "params": {"pyroscope_server": "71.76.51.175:4040"}, "state": "running"}'
后续测试过程默认成功安装并启动了stackprobe,为了不对被测程序性能造成影响,stackprobe也做了绑核操作,本次测试绑核cpu4。
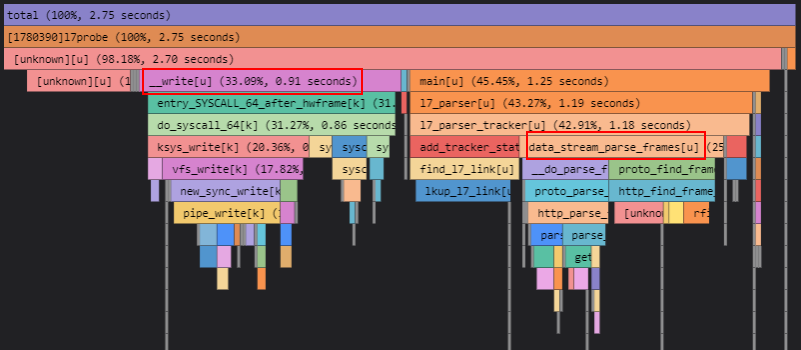
通过上图火焰图,可以看到目前执行耗时长的前三个函数如下:
top1: __write (怀疑是DEBUG打印引起)
top2: data_stream_parse_frames (用户态消息数据查找边界+报文解析流程)
top3: add_tracker_stats (用records刷新link_hash_table)
优化点一
针对top1,怀疑debug日志打印引起cpu占用过高;
被测程序l7probe关闭debug打印,服务端依然采用app.py,JMeter施压不变测试,测试结果如下:

可以看到平均CPU占用优化明显,查看火焰图可以看到,原本__write函数占比几乎没有了。

第二轮测试
火焰图分析
第一轮优化后,测试看到add_tracker_stats调用CPU占比很高,其中主要是lkup_l7_link函数,但是分析代码可知该函数内部只有一个hash查表,目前压测场景hash表只有一个元素,不应该是查找导致的耗时高。因而怀疑是否该函数被调用次数过多。
涉及的源码大致如下:
void l7_parser_tracker(struct l7_mng_s *l7_mng, struct conn_tracker_s* tracker) {
...
data_stream_parse_frames(msg_type, &(tracker->send_stream));
data_stream_parse_frames(msg_type, &(tracker->recv_stream));
// add stats
add_tracker_stats(l7_mng, tracker); // 调用次数55074686
...
return;
}
void data_stream_parse_frames() { // 调用次数110149372
1. peek_raw_data
2. if raw_data == NULL, return
3. if raw_data != NULL, proto_find_frame_boundary // 调用次数1016437
}
使用gdb看下每个函数调用次数:

如上图所示,data_stream_parse_frames调用次数和add_tracker_stats调用次数符合代码逻辑;但是data_stream_parse_frames是proto_find_frame_boundary调用次数的100倍!
继续分析add_tracker_stats函数主要是将records中的内容更新到hash表中。依然通过gdb查看调用次数:

由源码可看出,大部分情况中raw_data为NULL,会直接跳出循环。考虑raw_data为NULL的情况是否可以不用add_tracker_stats。gdb下看到事实上大部分都是空的,所以后续的更新link的操作都是无效或者没必要的。
优化点二
避免find_l7_link执行次数过多,执行前加判空操作。
add_tracker_stats {
// 问题点:函数没有做判断,那么即使records为空也要执行一遍find_l7_link
// 增加判空操作
if (tracker->records.record_buf_size == 0){
return;
}
link = find_l7_link(l7_mng, (const struct conn_tracker_s *)tracker); // hash find link
link->stats[REQ_COUNT] += tracker->records.req_count; // 用 records的数据更新link的内容
link->stats[RSP_COUNT] += tracker->records.resp_count;
link->stats[ERR_COUNT] += tracker->records.err_count;
for (int i = 0; i < tracker->records.record_buf_size && i < RECORD_BUF_SIZE; i++) {
.... // 时延统计相关的计算
}
}
测试结果
修改后火焰图分析可看出,add_tracker_stats的cpu占比减少很多:
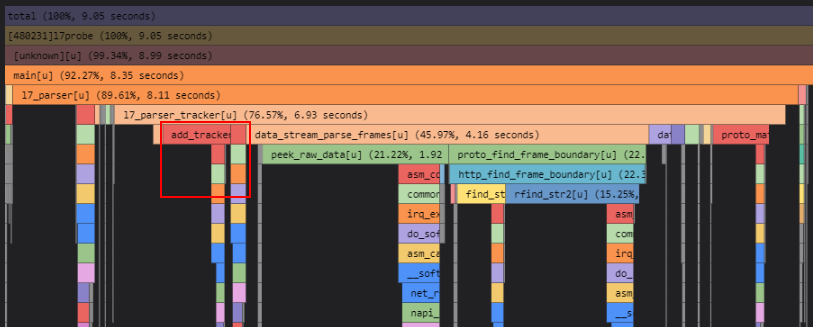
但是测试遇到一个问题:被测程序l7probe在修改前后的CPU占用变化不大;但是火焰图变化很明显。分析是因为修改使得l7probe的处理能力增强,l7probe是epoll_wait等待bpg_perf_buf的数据,等到数据然后处理,这里考虑之前的代码处理能力较低。后续测试降低JMeter压力:采用100线程并发测试。
第三轮测试
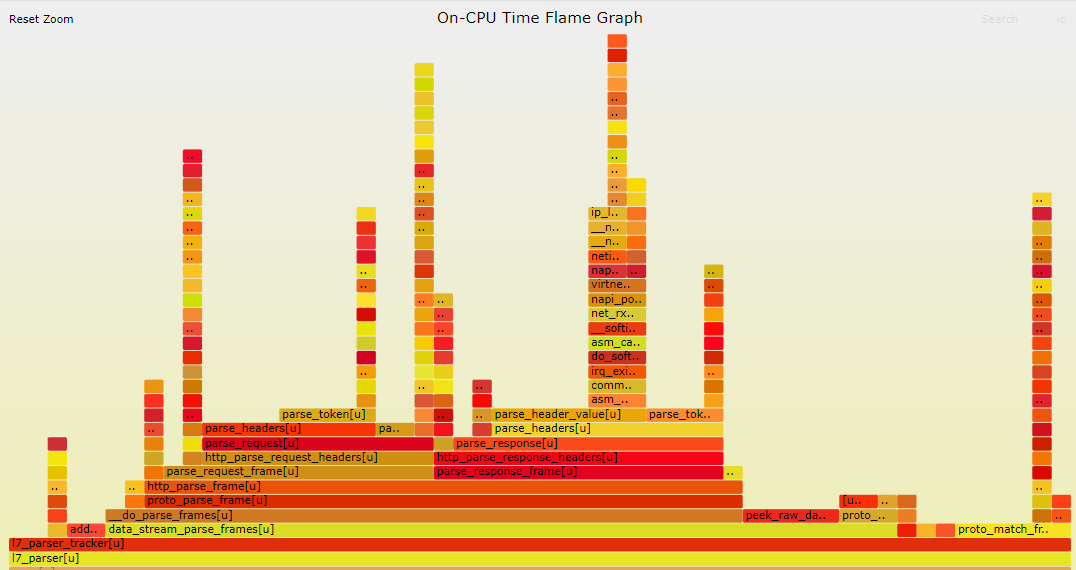
火焰图分析
上述火焰图中,可以看到现在data_stream_parse_frames执行时间最长,其中主要是proto_find_frame_boundary函数占用时间长。首先从代码层面优化,目前proto_find_frame_boundary源码如下:
size_t http_find_frame_boundary(enum message_type_t msg_type, struct raw_data_s *raw_data) {
// 1. Find the first "\r\n\r\n" sub-string position in the raw_data.data
size_t marker_pos = find_str(raw_data->data, BOUNDARY_MARKER, raw_data->current_pos);
// 2. Find sub-string: raw_data.data[start_pos, marker_pos]
// 将字符串拷贝到buf_substr中
char *buf_substr = substr(raw_data->data + raw_data->current_pos, start_pos, marker_pos - start_pos);
// 3. Match start_pattern in raw_data.data[start_pos, marker_pos], take the last one as frame boundary
for (int i = 0; i < patterns_len; i++) {
size_t current_substr_pos = rfind_str(buf_substr, start_pattern);
}
}
上述代码主要为了找到报文边界,主要是起始边界,方便后续http解析器处理报文。三个步骤中涉及大内存频繁申请释放,以及多次strlen、strncmp、strncpy等操作,具体参考优化点列举。
修改内部代码实现,测试结果如下,可以看到优化效果一般:
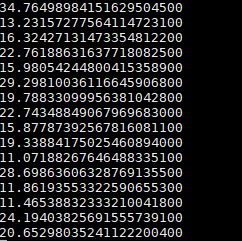
继续分析发现,http_find_frame_boundary 函数为了找到raw_data边界,主要考虑例如 “GET…PUT…POST…\r\n” 的异常情况,需要获取到POST对应的P的位置;
实际测试中这种情况不多,考虑是否可以为了性能取消执行find_frame_boundary操作 。
优化点三
参考其他开源项目如http_parser、kindling等,并简化http_find_frame_boundary实现方式:从头查找start_pattern,找到即停止。大致实现如下:
size_t http_find_frame_boundary(enum message_type_t msg_type, struct raw_data_s *raw_data)
{
// March start_pattern in raw_data.data from raw_data.current_pos
for (int i = raw_data->current_pos; i < raw_data->data_len; i++) {
for (int j = 0; j < ARRAY_NR(g_start_patterns); j++) {
if (strncmp(raw_data->data + i, g_start_patterns[j].name, g_start_patterns[j].name_len) == 0) {
return i;
}
}
}
return -1;
}
测试结果
优化后测试结果如下:
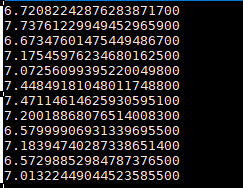
可以看到CPU占用优化效果明显。其实stackprobe运行过程会在/var/log/gala-gopher/stacktrace/下生成对应的svg文件,比如本轮测试我直接取了/var/log/gala-gopher/stacktrace/oncpu/2024-01-08/2024-01-08-16-52-08-521380.svg文件。浏览器直接打开如下图:
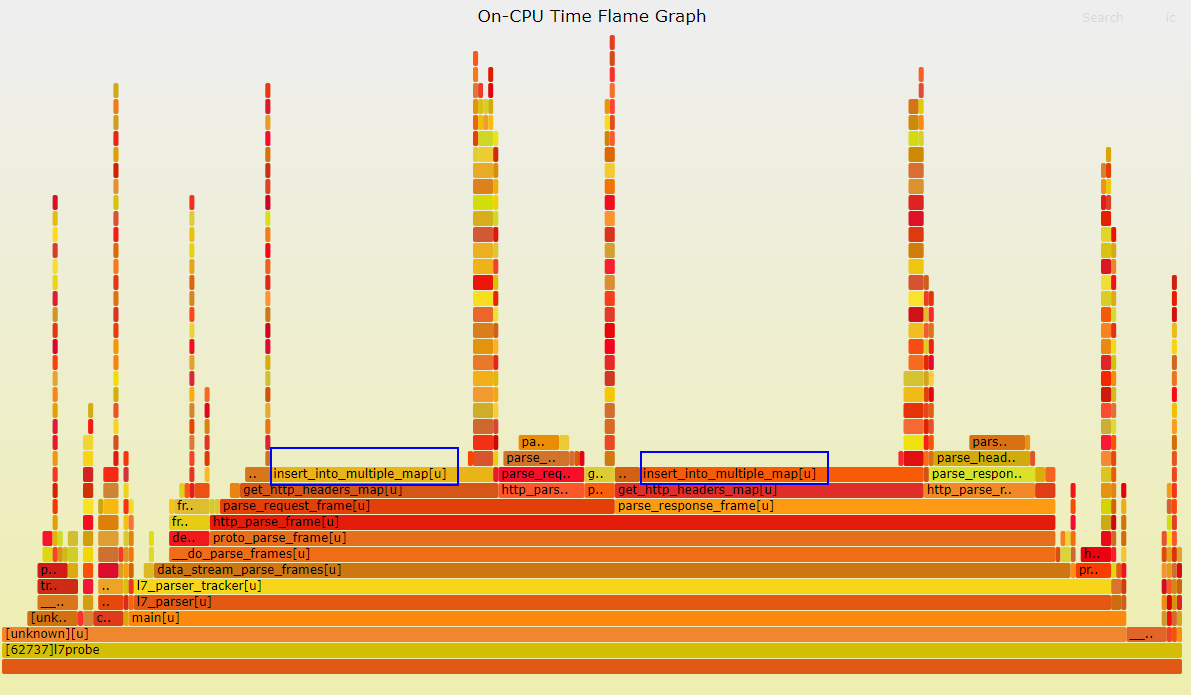
可以看到
data_stream_parse_frames 执行时间显著缩小。
第四轮测试
火焰图分析
由上轮压测的火焰图可以看到,目前蓝色方框内的get_http_headers_map函数执行耗时最大。分析代码可知,该函数主要是将报文头的内容以key和value的形式存入hash map中。该hash map使用的地方是parse_request_body/parse_response_body,即解析报文正文的时候。
由于报文头内容本来就少(几条)、使用的少(只需要获取"Content-Length" 和 “Transfer-Encoding”),以及仅在解析正文处使用,考虑删除hash表,直接遍历结构体数组查找。
优化点四
删除parse_request_frame/parse_response_frame中get_http_headers_map的调用;
修改parse_request_body/parse_response_body中"Content-Length" 和 "Transfer-Encoding"获取方案:直接遍历数组获取。修改大致如下
// 删除 get_http_headers_map 函数调用
// parse_request_body/parse_response_body增加函数入参,将http_headers数组传递进去
static parse_state_t parse_request_body(struct raw_data_s *raw_data, struct http_header headers[], int num_headers, struct http_message *frame_data)
// parse_request_body/parse_response_body内部直接遍历数组查找
// 新增get_http_header_value_by_key函数
int get_http_header_value_by_key(struct http_header headers[], size_t num_headers, char *key, char *value, int vlen_max)
{
if (key == NULL || value == NULL) {
return -1;
}
int klen = strlen(key);
for (size_t i = 0; i < num_headers; i++) {
if ((headers[i].name_len == klen) && (strncmp(headers[i].name, key, klen) == 0)) {
int vlen = (headers[i].value_len < vlen_max) ? headers[i].value_len : (vlen_max - 1);
(void)snprintf(value, vlen + 1, "%s", headers[i].value);
return 0;
}
}
return -1;
}
测试结果
被测程序l7probe单核100连接下,测试平均CPU占用**5%**左右:
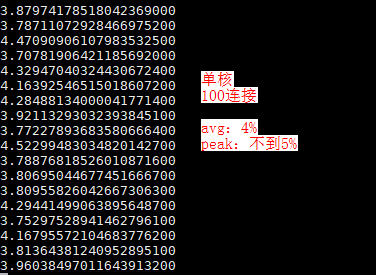
同样观察火焰图,可以看到http_headers_map 的执行时长几乎没了,整个parse_request_frame/parse_response_frame的执行时长也少了。
至此,优化暂时告一段落。