-
测试环境:
Server: Taishan 200.
OS: openEuler-22.03-LTS版本
GPU: Tesla V100 -
操作步骤:
在正常运行的系统中,执行gpu_burn压力测试.
2.1. 下载gpu压力测试用例:
https://github.com/wilicc/gpu-burn.git2.2. 执行make命令编译并运行压力测试程序.
[root@localhost gpu-burn]# make
[root@localhost gpu-burn]# ./gpu_burn -d 3600 -
系统现象:
3.1. 测试程序运行过程中,终端出现硬件错误的log: Hardware error from APEI Generic Hardware Error Souce: 10
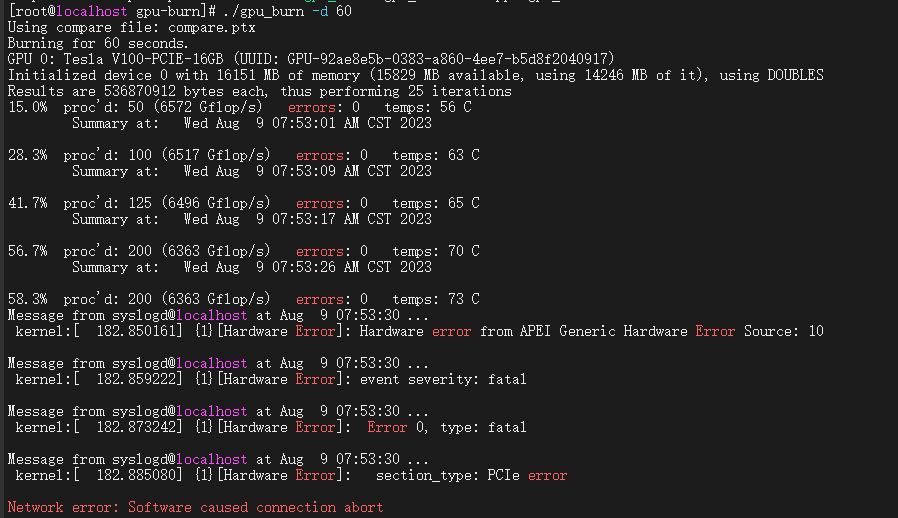
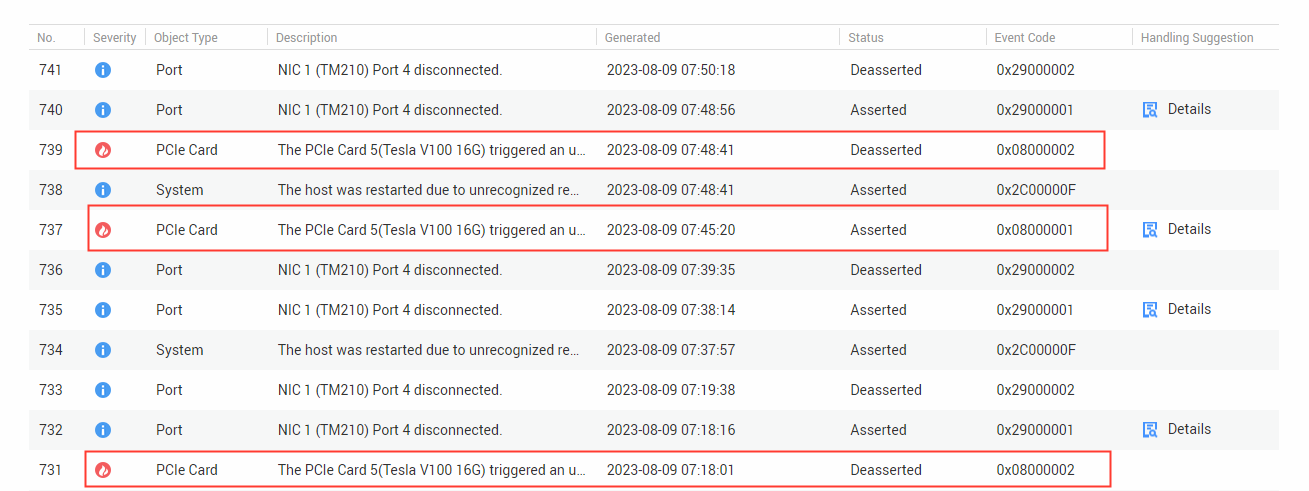
3.2. 通过服务器的iBMC可以看到系统告警: The PCIe Card 5(Tesla V100 16G) triggered an uncorrectable error。
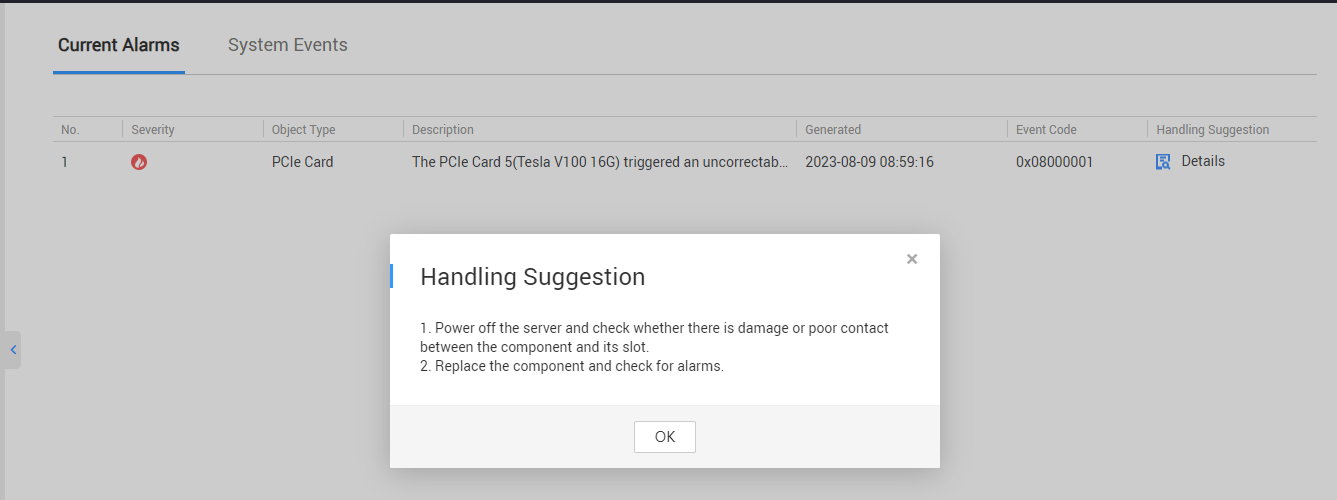
3.3. iBMC界面中系统提示的处理建议。
-
排查错误的整个过程以及所做的实验:
4.1. 运行驱动自带的nvidia-smi查询设置命令(如: nvidia-smi -q)能正常执行。
4.2. 进行短时间的压力测试,能完成测试(如: ./gpu_burn -d 5),系统没有出现重启现象。
4.3. 让机器关机一个小时,让GPU和服务器温度降下来,重新跑GPU压力测试,测试结果系统仍然重启,不过运行的时间稍微长了一点。
4.4. 根据iBMC提示,重新插拔GPU,重启系统问题依旧存在,并且偶尔出现lspci命令无法发现该设备。
4.5. 把该卡拔出放到超聚变X86_64服务器进行测试,同样会偶尔出现lspci命令无法发现该设备,并且长时间压力测试同样会出现系统重启的情况(说明下:这块卡在Taishan 200上测试前,已经在超聚变X86_64服务器运行过完整的测试,并且全部通过测试,没出现任何问题) 。
经过了对比测试,可以基本断定Tesla V100的硬件存在问题,再者通过观察压力测试时的温度,基本断定该故障跟GPU的温度有关联,温度稍微一升高,GPU就变的不稳定,很快就会触发硬件故障,导致系统重启。
4.6. 把该卡寄回到GPU供应商处检测,检测结果同样为硬件故障,供应商同意换块新卡。