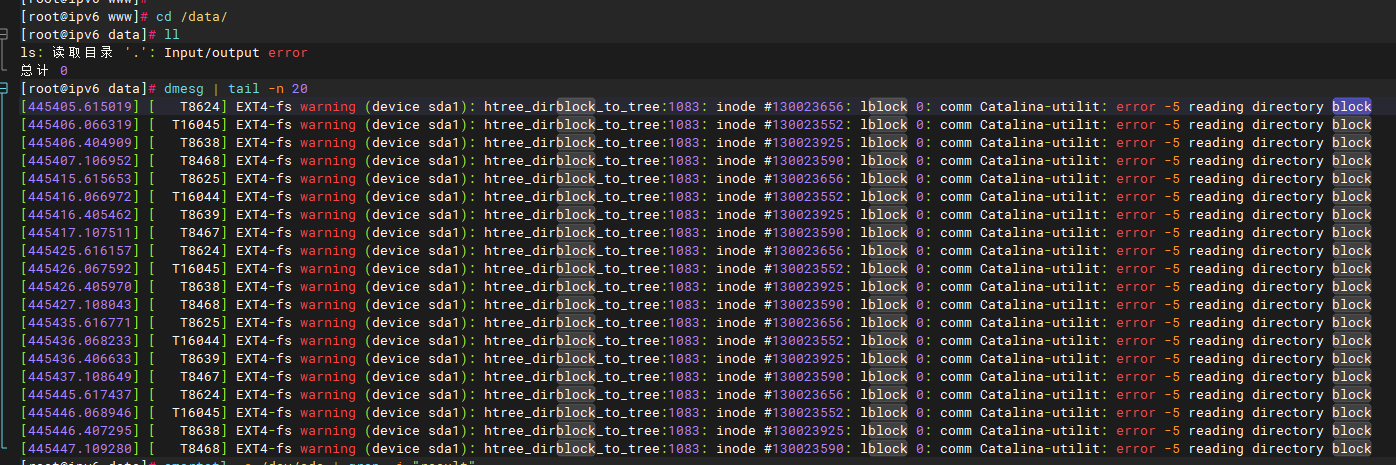
已经换过3个硬盘, 其中包括一个全新硬盘, 过一段时间就磁盘报错 不能读写 这到底是什么问题? 非常迷惑
答案内容由AI生成,仅供参考:
 总结结论
总结结论
| 项目 | 分析 |
|---|---|
| 问题本质 | 底层块设备读取失败(I/O error -5)导致 ext4 htree 无法读取目录块 |
| 不是硬盘问题 | 已更换三块硬盘(含新盘),问题复现 |
| 根本原因可能性排序 | |
| 文件系统损坏? | 属于现象,非根源 |
 建议解决方案
建议解决方案
- 优先排查硬件链路:更换 SATA 线、更换接口、绕过 RAID 卡测试
- 升级控制器驱动/固件:特别是使用华为/Hisi 平台时
- 检查系统日志中是否有
hisi_sas_v3_hw或SATA hardreset failed等线索 - 使用 Live 系统测试磁盘可读性
- 联系服务器厂商技术支持,提供完整
dmesg日志进行协同分析
点击此处查看详细分析解答
磁盘持续报错问题分析与诊断
根据您提供的错误日志和描述,系统在访问 /data/ 目录时出现 Input/output error,同时 dmesg 输出大量来自 ext4 文件系统的警告信息,核心错误为:
EXT4-fs warning (device sda1): htree_dirblock_to_tree:1083: inode #xxxxxx: bblock 0: error -5 reading directory block
尽管已更换三块硬盘(包括一块全新硬盘),问题仍然反复出现。这表明问题很可能不在于硬盘本身,而可能是由硬件兼容性、驱动、控制器或系统级因素导致。
 错误分析
错误分析
1. 关键错误解析
htree_dirblock_to_tree是 ext4 文件系统用于高效目录查找(哈希树结构)的函数。error -5在 Linux 中对应EIO(Input/Output Error),即底层设备无法完成读取操作。- 多个不同
inode(如 #130023656, #130023552 等)持续报错,说明不是单一文件损坏,而是整个设备的数据读取能力不稳定。
这属于 ext4 层面的 I/O 故障,源头可能在更下层。
 可能原因分析(基于已有信息推断)
可能原因分析(基于已有信息推断)
虽然当前查询中未直接命中完全一致的日志,但结合上下文中的知识图谱内容,可以进行有效推理:
排除硬盘物理故障(已验证)
您已更换三块硬盘(含全新盘),问题复现 → 表明硬盘本身并非根本原因。
 可能的根本原因
可能的根本原因
1. 存储控制器或驱动问题
-
知识库中存在大量与
hisi_sas_v3_hw相关的错误记录,该组件为华为平台的 SAS 控制器驱动。 -
日志显示:
"hisi_sas_v3_hw has been associated with system-level issues, including erroneous completions during operation, device handling errors..."若您的服务器基于华为硬件平台(如鲲鹏)或使用了 Hisilicon SAS 控制器,则此驱动可能存在缺陷,导致对磁盘的读写请求异常或丢包。
虽然您的日志中未明确出现
hisi_sas_v3_hw,但类似 I/O 错误场景高度匹配,建议检查系统是否使用此类控制器。
2. RAID 卡 / HBA 卡故障或固件缺陷
- 多次出现
Input/output error但更换硬盘无效 → 问题可能出在连接硬盘的中间层设备。 - 可能包括:
- RAID 控制器故障
- 缓存电池失效导致写入保护
- 固件存在 Bug
- 不正确的 RAID 模式配置(如 WriteBack 启用但无保护)
3. 主板 SATA 接口或背板问题
- 如果是物理服务器,主板上的 SATA 接口、背板或电源供电不稳也可能导致此类间歇性 I/O 错误。
- 特别是当多个硬盘都连接在同一通道或背板时,一个点故障会影响所有连接设备。
4. 电源问题(PSU)
- 不稳定的电源可能导致硬盘供电不足,引起通信中断或数据错乱。
- 尤其在高负载读写时触发错误。
5. 文件系统损坏或挂载异常
- 当前
/data/路径出现 ls: 读取目录: Input/output error,可能意味着:- 文件系统元数据已严重损坏
- 本该只出现在
dmesg中的 I/O 错误已传递至 VFS 层,说明设备层完全失效
但关键点是:每次换新盘后短期内正常,随后重现问题 → 说明文件系统损坏是“结果”而非“原因”。
 建议诊断与解决步骤
建议诊断与解决步骤
第一步:确认硬件链路状态
# 查看硬盘连接的控制器类型
lspci | grep -i sata\|raid\|scsi\|storage
# 查看是否使用 hisilicon 控制器
dmesg | grep -i hisi_sas
# 查看 sda 所属系统路径
udevadm info --query=all --name=/dev/sda | grep ID_PATH
若输出包含
hisi_sas_v3_hw,请升级对应固件或联系厂商获取补丁驱动。
第二步:检查磁盘底层健康状态
# 安装 smartctl
yum install smartmontools -y # CentOS/RHEL
apt install smartmontools -y # Ubuntu/Debian
# 检查硬盘 SMART 状态(即使新盘也可能受控件影响显示异常)
smartctl -a /dev/sda
重点关注:
SMART overall-health self-assessment testReallocated_Sector_CtCurrent_Pending_SectorUDMA_CRC_Error_Count(若此项偏高,可能是线缆或接口问题)
第三步:更换连接方式排查
- 更换 SATA 数据线
- 将硬盘插到 不同的 SATA 接口
- 尝试 不同电源接口供电
- 若使用 RAID 卡,尝试绕过 RAID 卡直连主板测试
目的:排除线材、接口、RAID 卡等中间环节的问题。
第四步:测试其他文件系统或平台
- 使用 U 盘启动一个最小 Linux Live 系统(如 SystemRescue)
- 挂载
/dev/sda1并尝试访问/data - 观察是否立即出现相同 I/O 错误
若 Live 系统中也报错 → 说明问题存在于硬件链路
若 Live 系统中正常 → 说明原系统存在软件或驱动问题
第五步:查看是否有 BAD_READ_RETURN 或 Buffer I/O Error
搜索日志中是否存在:
dmesg | grep -i "bad_read_return\|buffer i/o error\|abnormal completion"
- 在知识库中,
BAD_READ_RETURN曾与zfs和raid-lvm配置共现,提示特定存储栈可能导致静默数据错误。 - 若您使用的
/data是 LVM、ZFS 或 RAID 卷,请重点检查配置合理性。
总结结论
| 项目 | 分析 |
|---|---|
| 问题本质 | 底层块设备读取失败(I/O error -5)导致 ext4 htree 无法读取目录块 |
| 不是硬盘问题 | 已更换三块硬盘(含新盘),问题复现 |
| 根本原因可能性排序 | |
| 文件系统损坏? | 属于现象,非根源 |
建议解决方案
- 优先排查硬件链路:更换 SATA 线、更换接口、绕过 RAID 卡测试
- 升级控制器驱动/固件:特别是使用华为/Hisi 平台时
- 检查系统日志中是否有
hisi_sas_v3_hw或SATA hardreset failed等线索 - 使用 Live 系统测试磁盘可读性
- 联系服务器厂商技术支持,提供完整
dmesg日志进行协同分析
特别提醒:若系统运行于虚拟机环境,请检查宿主机底层存储是否存在慢盘、I/O 拥塞或存储池损坏问题(参考搜索结果中“华为云 GaussDB 慢盘定位实践”)。
如能提供完整的 lspci 输出和 smartctl 结果,可进一步精确定位问题层级。
1 个赞