gala 线程 profiling 功能介绍
概述
通过监控应用程序性能指标(如请求时延、吞吐量等),运维人员可以发现应用程序是否出现了性能问题。接下来,运维人员需要进一步定位出现性能问题的根因。通常的做法是,首先查看应用程序进程的 CPU、内存、I/O 等系统资源的占用情况。如果是 CPU 资源占用比较高,则需要进一步借助 CPU 火焰图等工具来进一步定位执行耗时的操作。如果 CPU 占用不高,则需要进一步定位是否由于等待 I/O 等资源导致的性能问题,比如磁盘 I/O 慢、网络 I/O 慢、以及出现锁竞争、死锁等情况。整个定位过程要求运维人员有着丰富的运维经验,以及熟悉各种运维工具的使用,定位时间长。
那么是否存在一种更加便捷直接的方法来定位应用性能问题呢?从操作系统的视角来看,一个应用程序是由多个进程组成,每个进程是由多个运行的线程组成。如果在程序的运行过程中,能够将这些线程执行的一些关键行为(后面称之为”事件“)记录下来,然后在前端界面通过时间轴的方式进行展示,这样我们就可以很直观地看到这些线程在某段时间内正在做什么,是在 CPU 上执行还是阻塞在某个文件、网络操作上。当应用程序出现性能问题时,通过分析对应线程的关键性能事件的执行序列,快速地进行定位定界。基于这样一种解决思路,gala-ops 提供了线程级性能 profiling 的解决方案。
本文接下来分为几个部分:首先介绍 gala-ops 线程 profiling 功能的原理,以及如何在 gala-ops 中安装和使用线程 profiling 功能,最后结合几个性能问题的案例来说明如何使用线程 profiling 功能对应用性能问题进行定位定界(可直接进入该章节感受一下)。
gala-ops 线程 profiling 功能介绍
gala-ops 线程 profiling 是一个基于 ebpf 的线程级应用性能诊断工具,它使用 ebpf 技术观测线程的关键系统性能事件,并关联丰富的事件内容,从而实时地记录线程的运行状态和关键行为,帮助用户快速识别应用性能问题。
事件观测范围
应用性能问题通常是由于系统资源出现瓶颈导致,比如 CPU 资源占用过高、I/O 资源等待。应用程序往往通过系统调用访问这些系统资源,因此可以对关键的系统调用事件进行观测来识别耗时、阻塞的资源访问操作。
另外,根据线程是否在 CPU 上运行可以将线程的运行状态分为两种:oncpu 和 offcpu ,前者表示线程正在 cpu 上运行,后者表示线程不在 cpu 上运行。通过观测线程的 oncpu 状态,可以识别线程是否正在执行耗时的 cpu 操作。
gala-ops 线程 profiling 当前已观测的系统调用事件参见链接: tprofilingprobe ,大致分为几个类型:文件操作(file)、网络操作(net)、锁操作(lock)和调度操作(sched)。下面列出部分已观测的系统调用事件:
- 文件操作(file)
- read/write:读写磁盘文件或网络,可能会耗时、阻塞。
- sync/fsync:对文件进行同步刷盘操作,完成前线程会阻塞。
- 网络操作(net)
- send/recv:读写网络,可能会耗时、阻塞。
- 锁操作(lock)
- futex:用户态锁实现相关的系统调用,触发 futex 往往意味出现锁竞争,线程可能进入阻塞状态。
- 调度操作(sched):这里泛指那些可能会引起线程状态变化的系统调用事件,如线程让出 cpu 、睡眠、或等待其他线程等。
- nanosleep:线程进入睡眠状态。
- epoll_wait:等待 I/O 事件到达,事件到达之前线程会阻塞。
事件内容
线程 profiling 事件主要包括以下几部分内容。
- 事件来源信息:包括事件所属的线程ID、线程名、进程ID、进程名、容器ID、容器名、主机ID、主机名等信息。
- 事件属性信息:包括公共的事件属性和扩展的事件属性。
- 公共的事件属性:包括事件名、事件类型、事件开始时间、事件结束时间、事件执行时间等。
- 扩展的事件属性:针对不同的系统调用事件,补充更加丰富的事件内容。如 read/write 文件或网络时,提供文件路径、网络连接以及函数调用栈等信息。
事件输出
gala-ops 线程 profiling 事件内容整体是按照开源的 openTelemetry 事件格式对外输出,并通过 json 格式发送到 kafka 消息队列中。前端可以通过对接 kafka 消费线程 profiling 事件。
下面是线程 profiling 事件的一个输出示例:
{
"Timestamp": 1661088145000,
"SeverityText": "INFO",
"SeverityNumber": 9,
"Body": "",
"Resource": {
"host.id": "",
"host.name": "",
"thread.pid": 10,
"thread.tgid": 10,
"thread.comm": "java",
"container.id": "",
"container.name": "",
},
"Attributes": {
// common info
"event.name": "read",
"event.type": "file",
"start_time": 1661088145000,
"end_time": 1661088146000,
"duration": 0.1,
"count": 1,
// extend info
"func.stack": "read;",
"file.path": "/test.txt"
}
}
安装和使用
安装
gala-ops 是 openEuler 社区开源项目 A-Ops 中针对云基础设施灰度故障的应用级/系统级在线诊断工具,线程 profiling 探针 tprofilingprobe 集成在其中的 gala-gopher 组件内。另外,为了能够在前端用户界面使用线程 profiling 的能力,gala-ops 基于开源的 kafka + logstash + elasticsearch + grafana 可观测软件搭建了用于演示的线程 profiling 功能的用户界面,用户可以使用 gala-ops 提供的部署工具进行快速安装。
安装 gala-gopher
用户需要先安装好 gala-gopher,具体的安装部署说明可参考 gala-gopher文档 。安装好 gala-gopher 后,在配置文件(安装路径为 /etc/gala-gopher/gala-gopher.conf)中开启线程 profiling 探针,然后启动 gala-gopher。
{
name = "tprofiling";
command = "/opt/gala-gopher/extend_probes/tprofiling";
param = "";
switch = "on";
}
配置参数说明:
- switch:设置为 on 表示开启线程 profiling 功能。
- param:通过该参数可以指定要观测的进程范围,如
-f 123表示观测进程 ID 为 123 的进程,也可以使用逗号分隔指定多个进程,如-f 123,456。如果不通过-f指定进程,则默认使用 gala-gopher 提供的进程白名单(安装路径为/etc/gala-gopher/gala-gopher-app.conf)来匹配要观测的进程范围。
安装前端软件
线程 profiling 功能的用户界面需要用到的软件包括:kafka、logstash、elasticsearch、grafana。这些软件安装在管理节点,用户可以使用 gala-ops 提供的部署工具进行快速安装部署,参考:在线部署文档。
在管理节点上,通过 在线部署文档 获取部署脚本后,执行如下命令一键安装中间件:kafka、logstash、elasticsearch。
sh deploy.sh middleware -K <部署节点管理IP> -E <部署节点管理IP> -A -p
执行如下命令一键安装 grafana 。
sh deploy.sh grafana -P <Prometheus服务器地址> -E <es服务器地址>
使用
完成上述部署动作后,即可通过浏览器访问 http://[部署节点管理IP]:3000 登录 grafana 来使用 A-Ops,登录用户名、密码默认均为admin。
登录 grafana 界面后,找到 ThreadProfiling 的 dashboard。
点击进入线程 profiling 功能的前端界面,接下来就可以探索线程 profiling 的功能了。
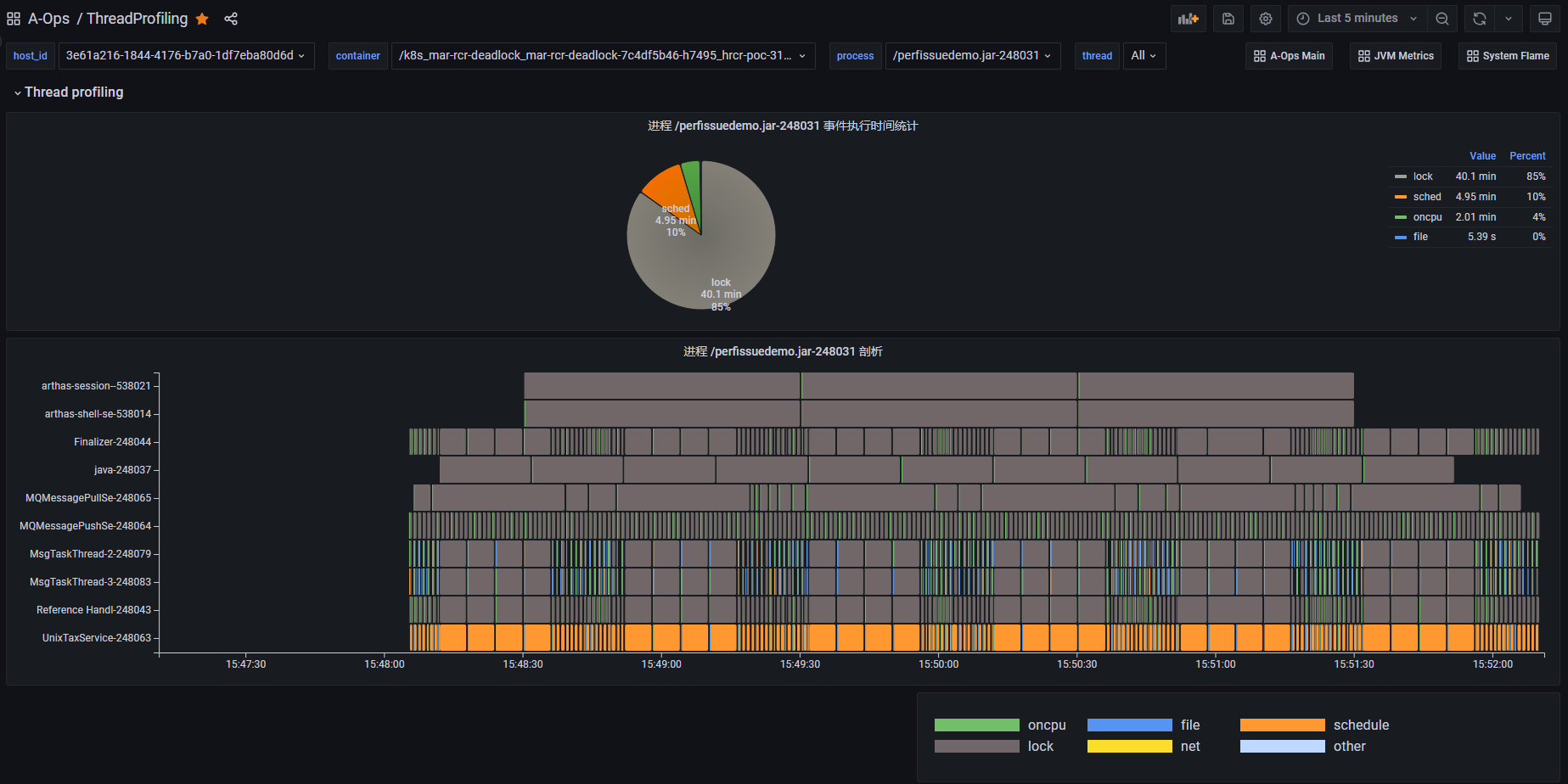
使用案例
案例1:死锁问题定位
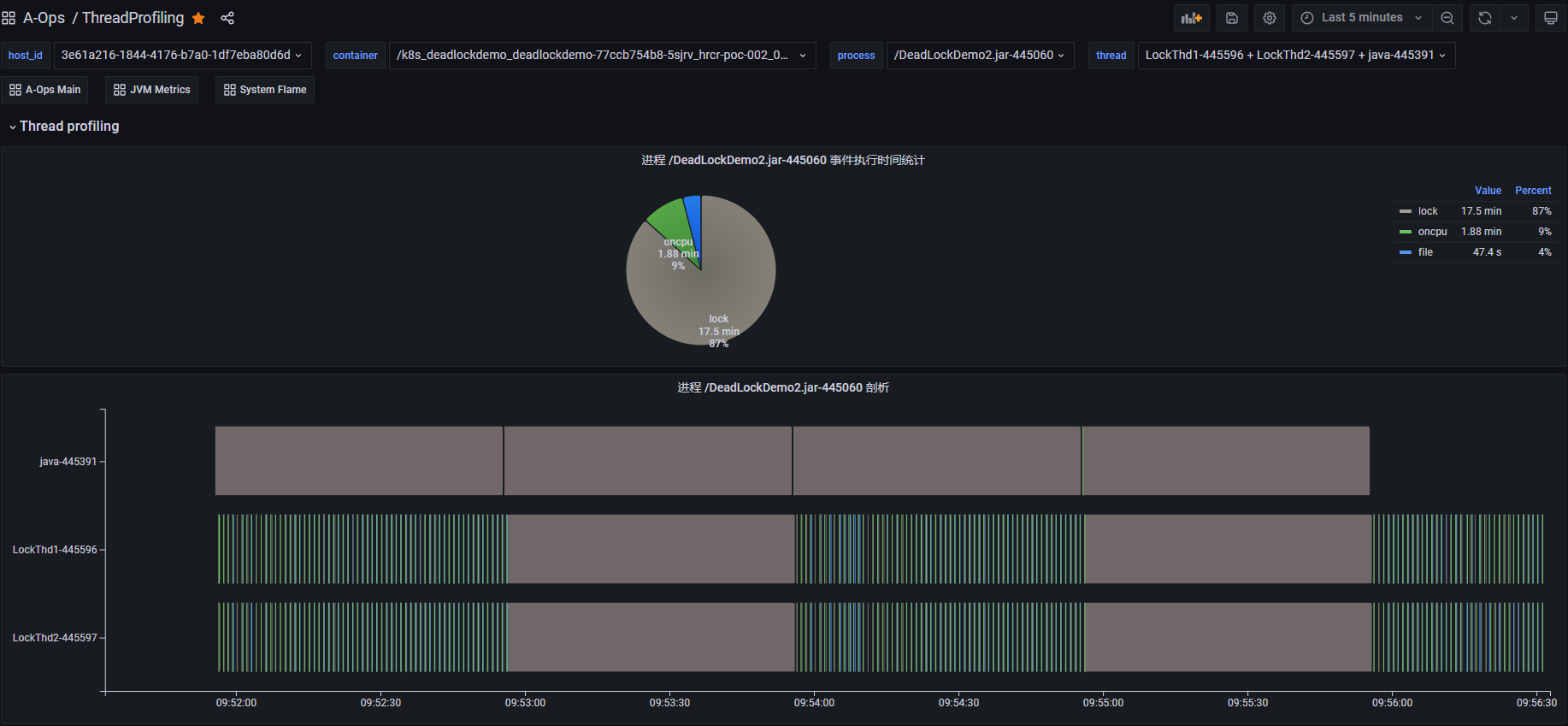
上图是一个死锁 Demo 进程的线程 profiling 运行结果,从饼图中进程事件执行时间的统计结果可以看到,这段时间内 lock 类型事件(灰色部分)占比比较高。下半部分是整个进程的线程 profiling 展示结果,纵轴展示了进程内不同线程的 profiling 事件的执行序列。其中,线程 java 为主线程一直处于阻塞状态,业务线程 LockThd1 和 LockThd2 在执行一些 oncpu 事件和 file 类事件后会间歇性的同时执行一段长时间的 lock 类事件。将光标悬浮到 lock 类型事件上可以查看事件内容,(如下图所示)它触发了 futex 系统调用事件,执行时间为 60 秒。
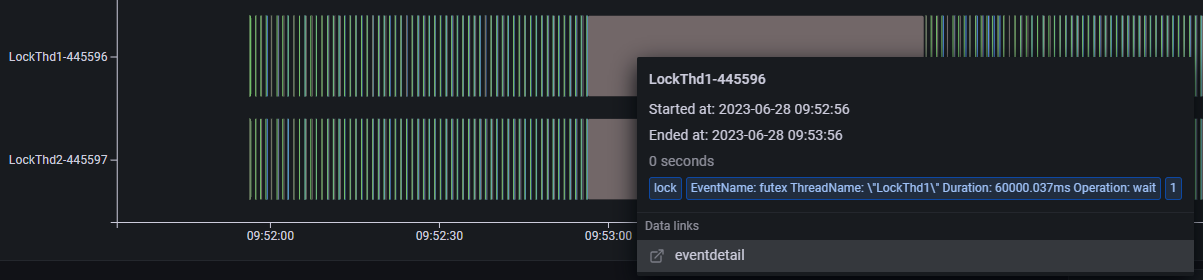
基于上述观测,我们可以发现业务线程 LockThd1 和 LockThd2 可能存在异常行为。接下来,我们可以进入线程视图,查看这两个业务线程 LockThd1 和 LockThd2 的线程 profiling 结果。
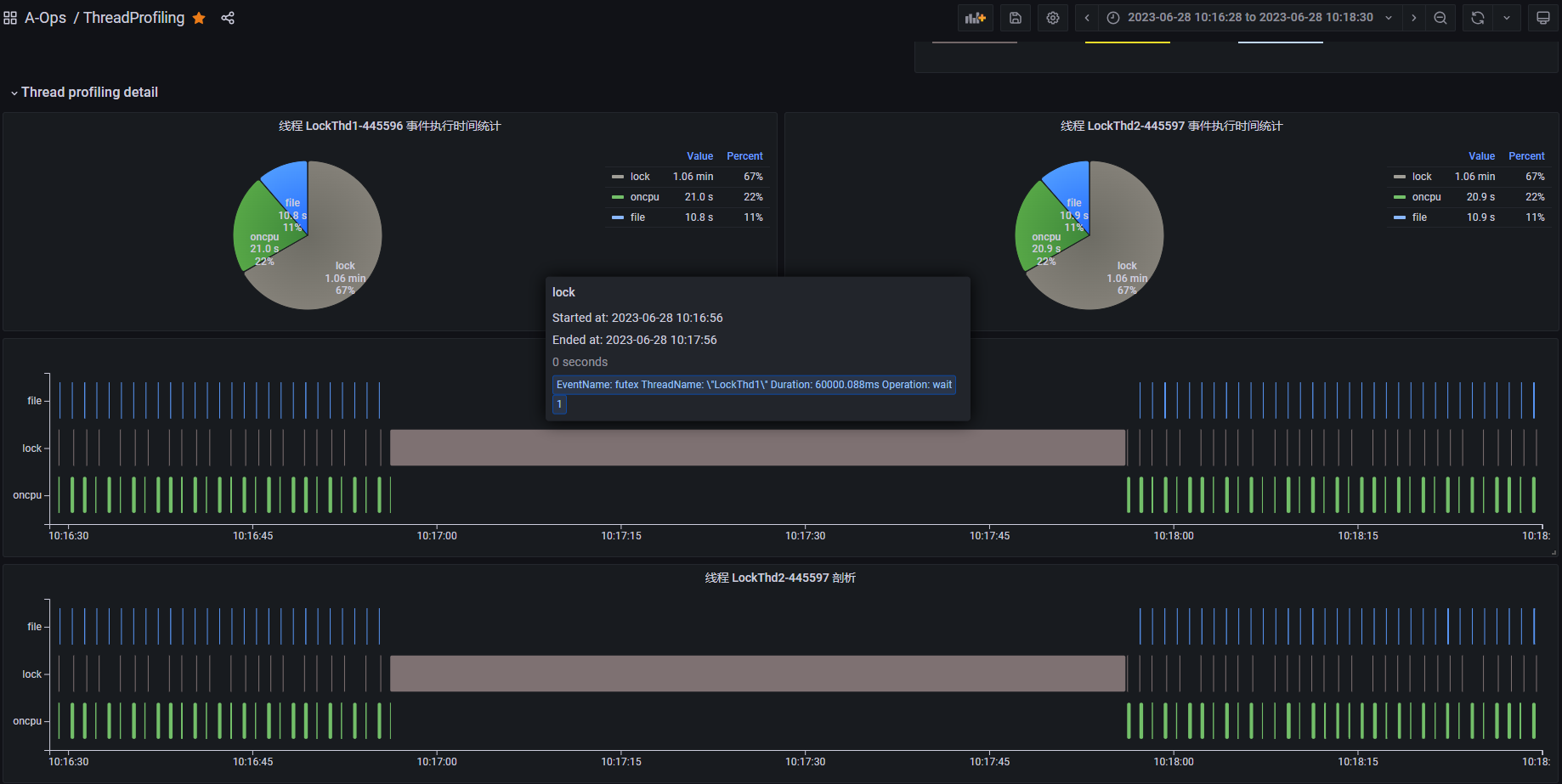
上图是每个线程的 profiling 结果展示,纵轴展示线程内不同事件类型的执行序列。从图中可以看到,线程 LockThd1 和 LockThd2 正常情况下会定期执行 oncpu 事件,其中包括执行一些 file 类事件和 lock 类事件。但是在某个时间点(10:17:00附近)它们会同时执行一个长时间的 lock 类型的 futex 事件,而且这段时间内都没有 oncpu 事件发生,说明它们都进入了阻塞状态。futex 是用户态锁实现相关的系统调用,触发 futex 往往意味出现锁竞争,线程可能进入阻塞状态。
基于上述分析,线程 LockThd1 和 LockThd2 很可能是出现了死锁问题。
案例2:锁竞争问题定位
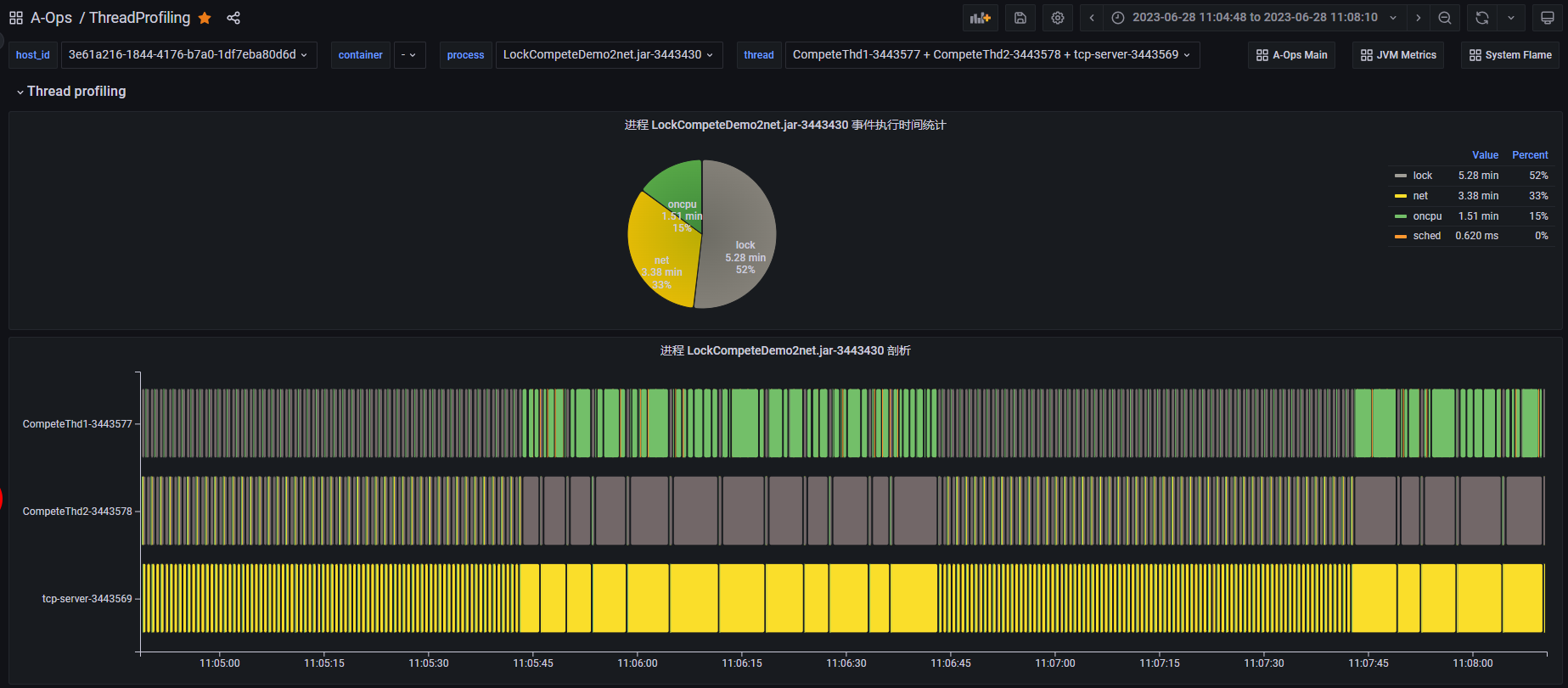
上图是一个锁竞争 Demo 进程的线程 profiling 运行结果。从图中可以看到,该进程在这段时间内主要执行了 lock、net、oncpu 三类事件,它包括 3 个运行的业务线程。在11:05:45 - 11:06:45 这段时间内,我们发现这 3 个业务线程的事件执行时间都变得很长了,这里面可能存在性能问题。同样,我们进入线程视图,查看每个线程的线程 profiling 结果,同时我们将时间范围缩小到可能有异常的时间点附近。
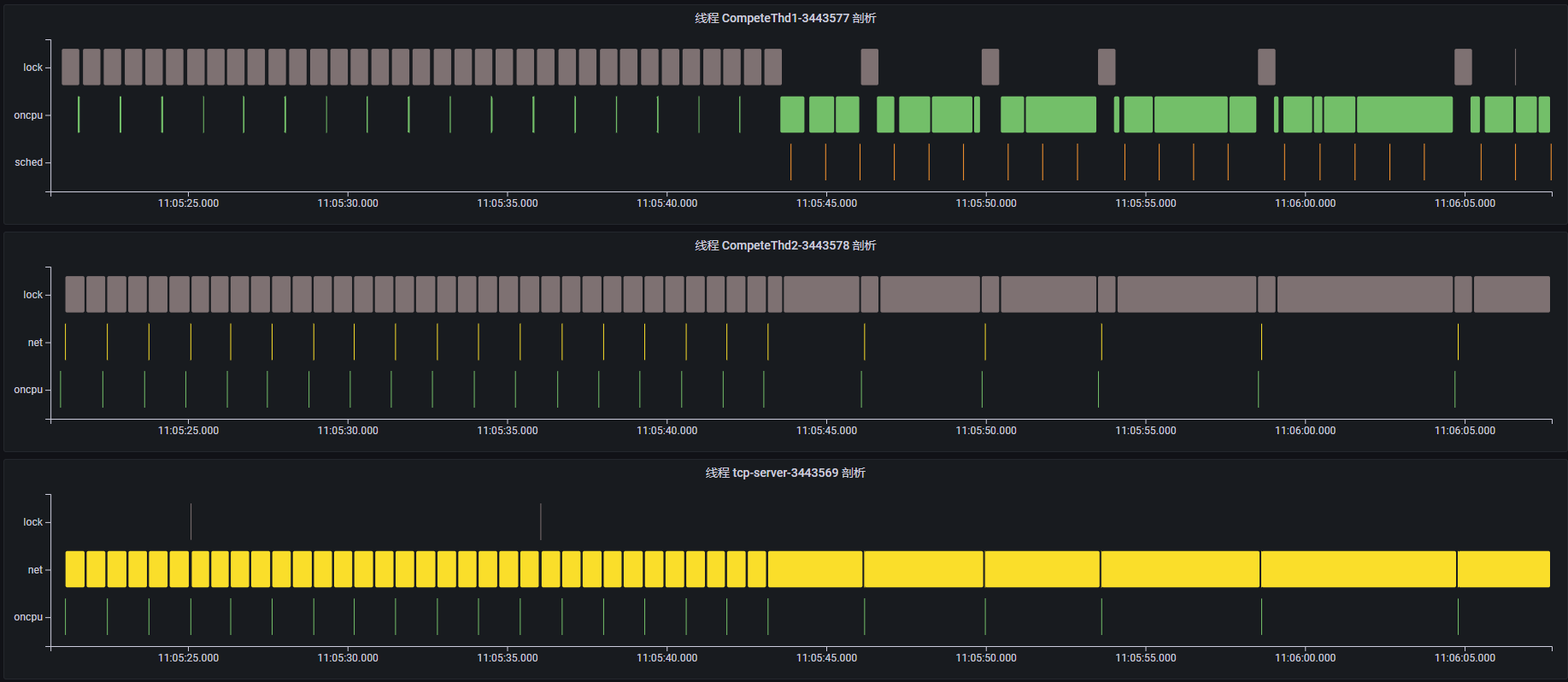
通过查看每个线程的事件执行序列,可以大致了解每个线程这段时间在执行什么功能。
-
线程 CompeteThd1:每隔一段时间触发短时的 oncpu 事件,执行一次计算任务;但是在 11:05:45 时间点附近开始触发长时的 oncpu 事件,说明正在执行耗时的计算任务。
-
线程 CompeteThd2:每隔一段时间触发短时的 net 类事件,点击事件内容可以看到,该线程正在通过 write 系统调用发送网络消息,且可以看到对应的 tcp 连接信息;同样在 11:05:45 时间点附近开始执行长时的 futex 事件并进入阻塞状态,此时 write 网络事件的执行间隔变长了。
-
线程 tcp-server:tcp 服务器,不断通过 read 系统调用读取客户端发送的请求;同样在 11:05:45 时间点附近开始,read 事件执行时间变长,说明此时正在等待接收网络请求。



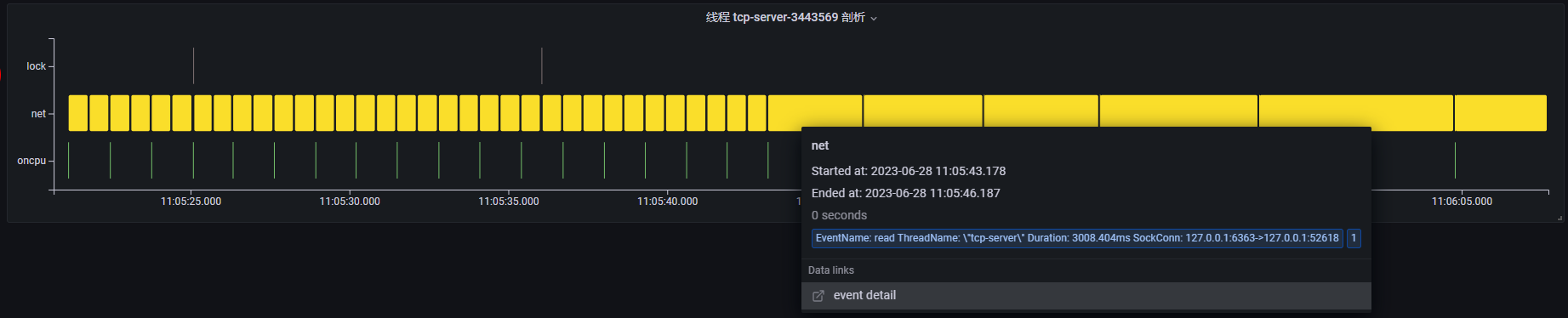
基于上述分析,我们可以发现,每当线程 CompeteThd1 在执行耗时较长的 oncpu 操作时,线程 CompeteThd2 都会调用 futex 系统调用进入阻塞状态,一旦线程 CompeteThd1 完成 oncpu 操作时,线程 CompeteThd2 将获取 cpu 并执行网络 write 操作。因此,大概率是因为线程 CompeteThd1 和线程 CompeteThd2 之间存在锁竞争的问题。而线程 tcp-server 与线程 CompeteThd2 之间存在 tcp 网络通信,由于线程 CompeteThd2 等待锁资源无法发送网络请求,从而导致线程 tcp-server 大部分时间都在等待 read 网络请求。