背景描述:
基于MLX BF2卡的弹性裸金属场景网络和存储性能测试。在FIO测试7:3混合读写场景,压测远端存储盘,压测4块盘时性能正常,压测8块盘时,性能下降明显。
存储方案模型:
存储后端通过BF2模拟的virtio-blk设备,访问远端的云盘。
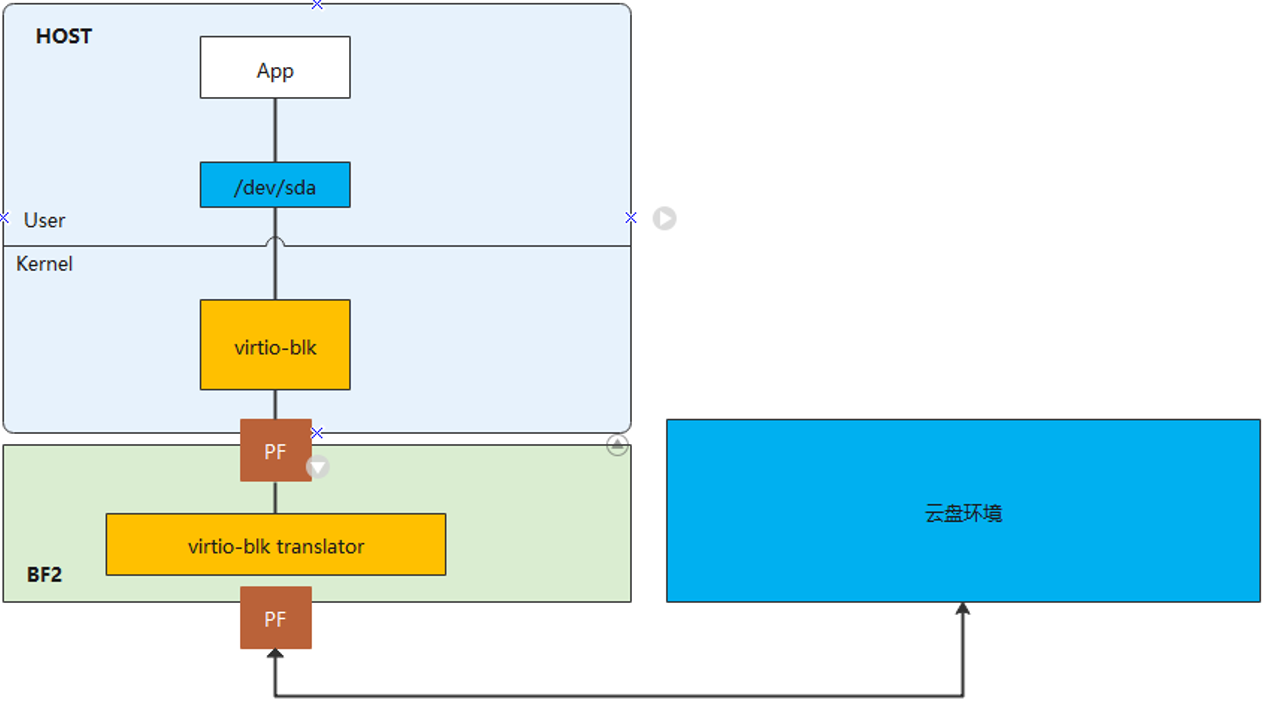
测试环境:
| 服务器 | 鲲鹏920 6426 |
|---|---|
| OS | CTyunOS |
| 内核 | 4.19 |
| DPU卡 | Mellanox BF2 |
原因分析
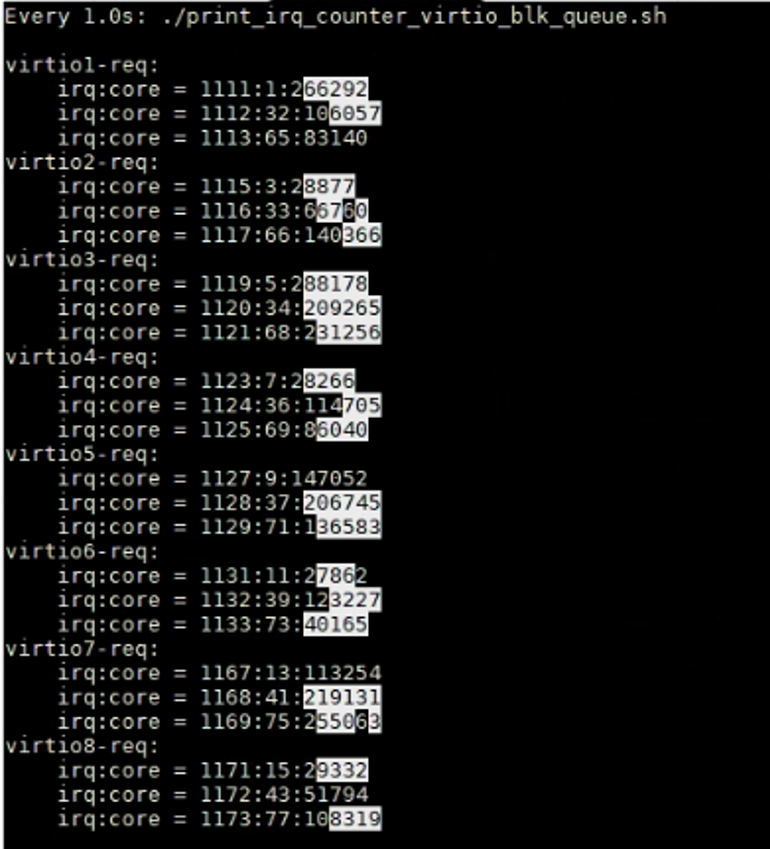
进一步分析性能瓶颈发现,在8盘同时压测情况下,中断都分配到0、32、64核心,处理中断的CPU被压满了,导致单核响应中断出现瓶颈。同样情况下,对比X86环境,中断较ARM场景会分散到多个CPU处理,性能达标。
下图中virtioX-req表示不同的设备盘对应的中断,当前环境下设置的MSI-X数为3,对应三个中断队列。数据的三列分别表示中断号、中断CPU、中断次数,可以看到所有盘的中断都集中在了0、32、64的核心上(分别为Numa0、Numa1、Numa2的第一个核)。

同样情况下,对比X86的中断亲和性配置文件,中断绑核是散列的。 客户使用的OS尝试修改亲和性文件,修改不成功。
尝试手动修改中断亲和性,有类似如下的报错:

经分析后,此报错确认是该LPI中断带了IRQD_AFFINITY_MANAGED flag,用户态无法设置亲和性,只能由内核分配。该flag为内核上游社区在4.8版本加入。
ARM架构下在映射LPI中断时,ITS(Interrupt Translation Service)驱动程序会从中断的亲和性列表和在线CPU的交集中选择第一个cpu,在大多数情况下是CPU0。如果多个中断亲和性被设置为cpu 0 - cpu xx,那么这些中断会集中送到cpu0上,导致cpu0负载过高,性能较差。由于ARM与x86架构下中断控制器差异,ARM架构LPI中断和X86 APIC中断实现机制不同,x86在APIC中断上实现了负载均衡,因而未出现该问题。
解决方法:
通过NV网卡工程师交流获悉,arm架构下CentOS 8.5 stream版本不存在中断无法散列问题。进一步验证,在CentOS 8.5 kernel-4.18.0.348下验证virtio-blk中断无法正常散列,CentOS 8.5 stream kernel-4.18.0.486验证virtio中断散列正常。初步定界2个内核版本间存在相关修复patch,结合中断流程机制,锁定LPI中断等相关patch。
2f13ff1d1d (“irqchip/gic-v3-its: Track LPI distribution on a per CPU basis”)
c5d6082d3 (“irqchip/gic-v3-its: Balance initial LPI affinity across CPUs”)
1dc440355 (“crypto: hisilicon/zip - add a work_queue for zip irq”)
经过分析,以上补丁主要通过找到“负载最少”的CPU(即映射到它的LPI中断较少的CPU)来放置中断,可以分散单个CPU处理LPI中断的性能开销,避免多个LPI中断集中在少数核上处理。
补丁作用范围和模块
该补丁只修改了ITS中断模块的驱动文件drivers/irqchip/irq-gic-v3-its.c,影响LPI中断在哪个CPU上处理,具体如下:
- 功能接口:its_set_affinity()和its_irq_domain_activate()
- 中断类型:managed 和unmanaged 的LPI中断
硬件平台:NUMA或者非NUMA平台,并且是多核平台
- 性能:降低某些CPU上的LPI中断负载,特别是能有效改善managed LPI中断的性能问题,因为managed LPI中断无法在用户态配置亲和性,而unmanaged LPI中断本身可以在用户态配置亲和性。
补丁实现原理分析
跟踪每个CPU的LPI中断数量
为了改善CPU之间的LPI分布,需要跟踪分配给CPU的LPI数量,包括managed中断和unmanaged中断:
- managed中断和unmanaged中断都用一个per cpu的计数器进行LPI中断数量计数

- 在its_set_affinity()函数设置LPI中断亲和性或者its_irq_domain_activate()激活一个LPI中断时根据中断managed属性进行相关CPU的相关中断计数器加1
- 在执行its_irq_domain_deactivat()函数停止分发一个LPI中断时根据中断managed属性进行相关CPU的中断计数器减1
不同CPU间进行LPI中断负载均衡
在its_irq_domain_activate()激活一个LPI中断时或者在设置中断亲和性时没有强制设置亲和性mask时,从可选目标CPU集合中选择一个LPI中断负载最轻的CPU。
在设置中断亲和性时,managed中断和非managed中断目标CPU不同:
- managed中断:分配的CPU mask和在线CPU mask的交集
- 非managed中断
- 中断绑定到NUMA节点:目标CPU由亲和性mask、节点mask决定
- 中断没有绑定到NUMA节点:目标CPU由亲和性mask和在线mask决定
最后,不管managed中断还是unmanaged中断,都通过cpumask_pick_least_loaded()函数从可选择的目标CPU集合中选择LPI中断数量最少的CPU,实现LPI中断的负载均衡,该函数实现原理为:
遍历所有可选CPU,根据managed属性从per cpu的相应计数器中获取每个可选CPU的LPI中断数量,然后从其中选择中断数量最少的CPU。
补丁相关维测接口
设置日志级别允许pr_debug输出时,可以打印为虚拟中断号irq选择的最轻LPI中断负载CPU,以及可选CPU集合aff_mask,便于分析和调试。
补丁验证测试
基于搭建的openEuler20.03 SP3环境,回合相关补丁,重新编译内核后,LPI中断可散列在各CPU核心上,中断瓶颈问题得到解决。Fio在8盘场景测试,补丁回合后,初步验证IO性能提升约60%。
资料参考
https://lore.kernel.org/all/20200316115433.9017-1-maz@kernel.org/
https://lore.kernel.org/all/20200316115433.9017-2-maz@kernel.org/
https://lore.kernel.org/all/20200316115433.9017-3-maz@kernel.org/
https://lore.kernel.org/all/87h80q2aoc.fsf@nanos.tec.linutronix.de/